The demo-to-production gap in AI agents
Your agent works perfectly in a demo. It reads files, calls tools, generates code, and produces exactly the output you expected. Then you deploy it. Within hours, it starts hallucinating tool parameters, losing track of multi-step workflows, and silently failing on edge cases nobody tested.
This is the agent reliability problem, and it is the single biggest barrier to production AI agent deployment in 2026. According to LangChain's State of AI Agents report, 57% of organizations now have agents in production — but 32% cite quality as their top blocker. The issue is not the model. It is the infrastructure between the model and the real world.

The harness pattern: orchestration as architecture
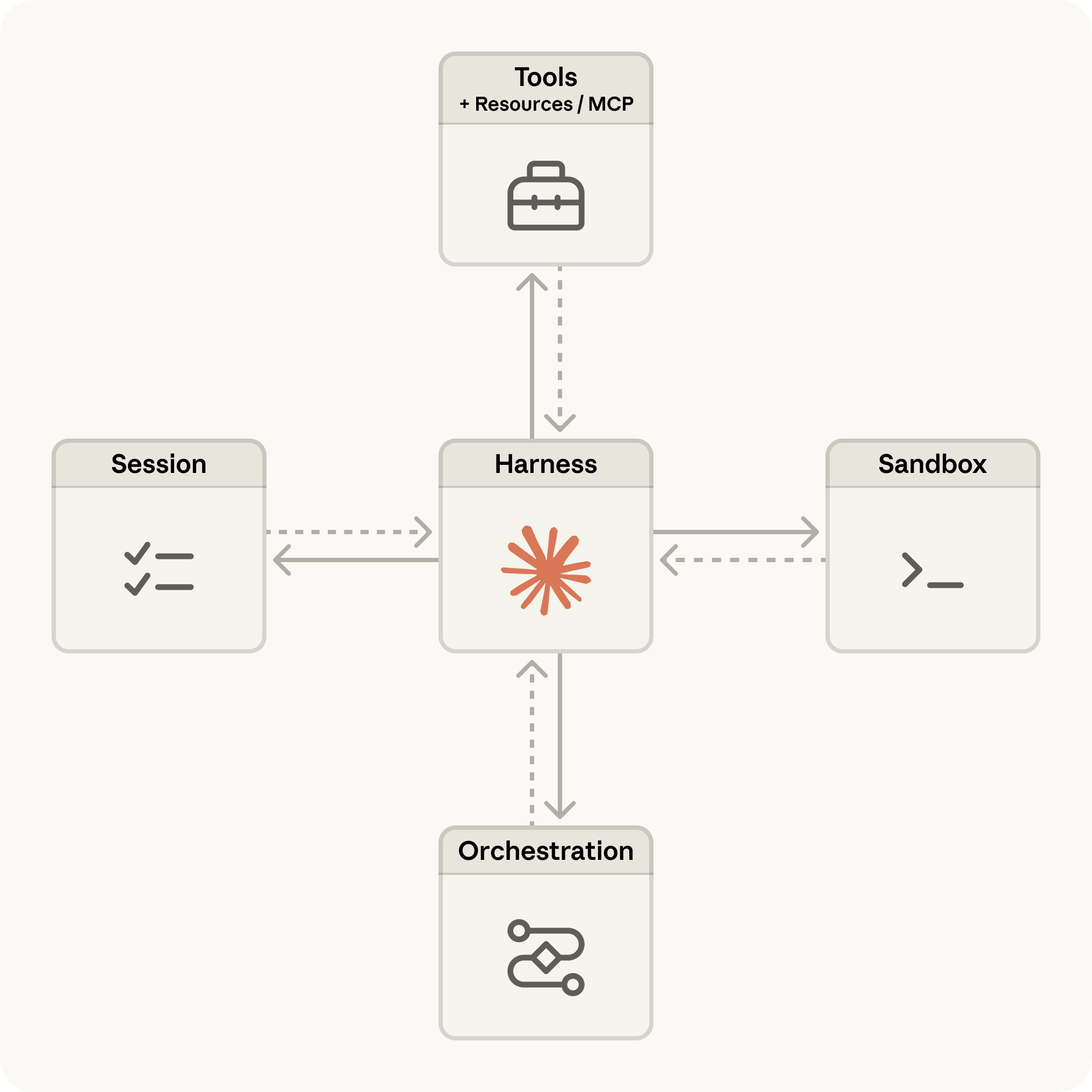
When Anthropic announced Claude Managed Agents on April 8, they did not just ship a hosting service. They introduced a specific architectural pattern: the agent harness. At the center of the system sits an orchestration layer that does not merely route tool calls — it determines which tools to invoke, manages execution context, handles error recovery, and coordinates multiple agents.
The harness connects to four subsystems. Tools and Resources are exposed via MCP, giving agents structured access to external capabilities. Sandboxed Execution provides isolated environments for code execution without risking the host system. Session State Management handles checkpointing and persistence, so long-running agents can resume after interruptions. And Multi-Agent Orchestration — still in research preview — enables agents to delegate subtasks to specialized peers.
This architecture matters because it separates the reasoning layer (what the agent decides to do) from the execution layer (how it safely does it). Most production agent failures happen at that boundary — and the harness pattern is designed to absorb them.
Self-evaluation closes the reliability gap
The most significant technical claim from Anthropic is not about infrastructure — it is about agent behavior. The harness enables Claude to self-evaluate intermediate results and iterate toward success criteria before returning a final output. In internal benchmarks on structured file generation tasks, this self-evaluation loop produced up to a 10-point improvement in task success over standard prompt-and-respond loops.
The gain is concentrated on complex problems. Simple tasks show marginal improvement — the model already gets them right. But on multi-step tasks with ambiguous requirements, the self-evaluation loop catches errors that would otherwise propagate silently through the workflow. The agent notices when a generated file is malformed, when a tool call returned unexpected data, or when the output drifts from the original spec.
This matters for the broader AI agent orchestration landscape. Gartner reports a 1,445% surge in multi-agent system inquiries since early 2024 — but most teams stall at quality assurance. Self-evaluation addresses that directly: instead of relying on external validators, the agent validates itself within the harness loop.
What early adopters reveal about the pattern
Five early production deployments show where the harness pattern delivers the largest gains. The common thread is not the use case — it is the infrastructure acceleration.
- Rakuten deployed specialist agents across product, sales, marketing, and finance — each one stood up in a single week. Custom agent infrastructure would have taken months per department.
- Sentry paired their Seer debugging tool with a Claude-powered agent that writes patches and opens pull requests. The pipeline from flagged bug to reviewable fix runs end-to-end without a developer in the loop.
- Notion integrated agents that execute long-running tasks across documents and databases, with persistent session state so work survives interruptions.
- Asana built AI Teammates that work alongside humans in project workflows, shipping advanced collaboration features faster than their original roadmap projected.
- Vibecode uses agents as default infrastructure for AI-native app deployment, establishing infrastructure at least 10x faster than previous timelines.
Applying the harness pattern to local agent workflows
You do not need Managed Agents to adopt the harness pattern. The architectural principles — separation of reasoning and execution, sandboxed tool access, session persistence, self-evaluation loops — apply equally to local agent development workflows.
Local agents already implement several of these subsystems. Session memory persists context across conversations. Scheduled tasks run agents autonomously with checkpointed state. Permission systems provide scoped tool access — the local equivalent of the governance layer. Browser automation runs in isolated contexts with full execution tracing. The pattern is the same; the execution environment differs.
The practical question for 2026 is not cloud versus local — it is which workloads belong where. Cloud-hosted agents handle headless, high-scale work: batch processing thousands of items, always-on autonomous tasks, enterprise-wide multi-agent deployments. Local agents handle interactive development, real-time feedback loops, and workflows that need direct access to your file system, Git repos, and running processes. The harness pattern makes both more reliable.